

Recreating the Rosetta Stone for Machine Translation of Low-Resource Languages
April 13, 2022 · 4 min read
-

VoxCroft Chief AI Scientist
Relevance is the secret ingredient to achieving far more accurate low-resource language translation models when data is scarce, as is typical for most of the world’s 7000+ languages
Machine learning models perform best when they are trained on data that is as similar as possible to the data that the model will see when deployed in the real world. When this doesn’t happen the predictions of machine learning models can be poor, biased or discriminatory, with serious consequences.
This is just as true in the field of machine translation. In 2017, Facebook’s machine translation algorithm translated a Palestinian man’s “Good morning” greeting as “hurt them” in English and “attack them” in Hebrew, leading to his arrest and questioning by the Israeli authorities [[1]](https://www.theguardian.com/technology/2017/oct/24/facebook-palestine-israel-translates-good-morning-attack-them-arrest). To prevent these kinds of errors with real world implications, machine translation technology needs to become better at understanding the context in which language is used.
VoxCroft Analytics seeks to address this challenge by creating high-quality translation data and neural translation models, especially among languages for which there is very little training data, as is the case for most of the world’s 7000+ languages, more commonly described as low-resource languages. Having little training data for a language makes the resulting model very sensitive to applications outside the domain of the training data.
VoxCroft has successfully built bilingual English-vernacular machine translation models for many low-resource African languages using a large training dataset of highly relevant, quality controlled translations of news content. Internally, we have called this dataset the Rosetta collection, in reference to the Rosetta Stone, a relic containing identical texts in three scripts, that allowed historians to decode ancient Egyptian hieroglyphics.
In contrast, a common approach taken in studying low-resource machine translation is to train models on publicly available translations of religious texts.
How well do machine translation models trained on religious texts perform on real-world news articles?
To answer this, consider the low-resource African languages Luganda, Oromo and Tigrinya, Luganda is spoken by at least half of Uganda’s 45 million citizens, while Oromo is an Afroasiatic language spoken in Ethiopia and northern Kenya. Tigrinya is a semitic language – sharing linguistic similarities with Hebrew and Arabic – spoken in Ethiopia and Eritrea.
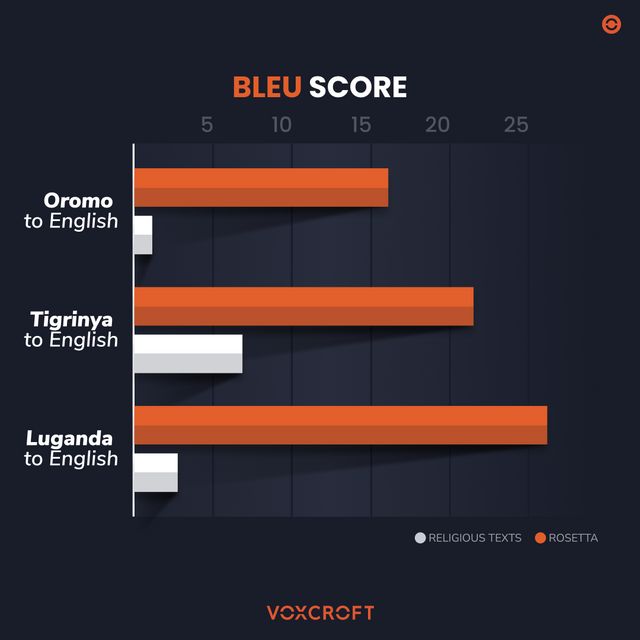
Table 1 below shows that even training on a large number of religious sentences typically leads to a model that performs very poorly on real-world news text. In contrast, a model trained on a much smaller set of relevant training data gives much better results.
One way to quantify performance of machine translation models is through the Bilingual Evaluation Understudy score, commonly known as the BLEU score. The BLEU score is a measure of the degree of similarity of a translation to reference translations provided by a team of native speakers (larger BLEU scores denote a greater degree of similarity).
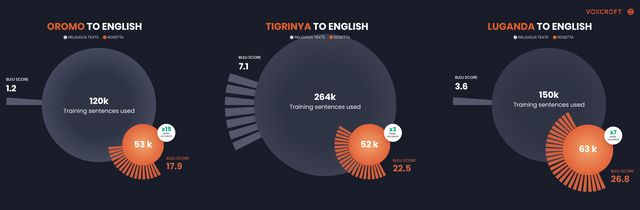
An Oromo-to-English model, trained on 120,000 religious sentences, achieved a BLEU score of just 1 when tested on the Rosetta real-world test set, despite getting a BLEU score of 21 when tested on religious sentences. In contrast, a machine translation model trained on just 53,000 Rosetta news sentences received a BLEU score of 18 on the complex real-world test set.
The same pattern is repeated for both Tigrinya and Luganda where the performance of models trained on the Rosetta real-world data was 3-7 times better than the Bible-trained models, despite the amount of Rosetta training data being 2-5 times smaller than the religious training data in each case (see Table 1).
| Model | Oromo To English (Training sentences in brackets) | Tigrinya To English (Training sentences in brackets) | Luganda To English (Training sentences in brackets) |
|---|---|---|---|
| BLEU Score: Religious Texts | 1.2 (120k) | 7.1 (264k) | 3.6 (150k) |
| BLEU Score: Rosetta | 17.9 (53k) | 22.5 (52k) | 26.8 (63k) |
| Improvement Factor from Religious Texts to Rosetta | x14.9 | x3.2 | x7.4 |
TABLE 1: Machine translation model performance for Oromo, Tigrinya and Luganda depends strongly on the quality of training data. Models trained on even small amounts of the VoxCroft Rosetta training datasets scored significantly better than those trained on publicly available Religious translation data.
This demonstrates how relevant training data can be 20-30 times more valuable per sentence than translation data from a different domain.

How does this reflect in the actual translations? Consider the following sentence in Oromo:
“Loltoonni al-Shabaab sadi aanaa Beled Hawo kan Gobolka Gedo keessatti argamu keessatti humna waraana biyyaalessaa Sumaaliyaatti harka kennataniiru."
This was translated by a native speaker as:
“Three al-Shabaab fighters have surrendered to Somali National Army forces in the district of Beled Hawo in Gobolka Gedo.”
The Religious texts-trained model translates this as:
“Three Webite robes were given by the Big Red Islands — a power over the Syrian River”
In contrast, our Rosetta-trained model, despite being trained on a dataset less than half the size, gives the translation:
“Three al-Shabaab fighters have handed over the Somali National Army forces in the district of Beled Hawo in Gobolka Gedo.”
Not perfect, but significantly better, despite the much smaller training set.

Consider another example, this time from Tigrinya:
ቀዳማይ ሚኒስተር ኢትዮጵያ ኣብይ ኣህመድ ብ29 ሓምለ ንግሆ ምስ መራሕቲ ተቓውሞ ምይይጥ ገበረ ።
Which was translated by humans as:
“Ethiopian Prime Minister Abiy Ahmed held discussions with opposition leaders on the morning of 29 July.”
The Rosetta-based model translated it as:
“Ethiopian Prime Minister Abiy Ahmed held meetings with opposition leaders on the morning of 29 July.”
While the Religious texts-based model instead wrote:
“prime minister ethiopian spoke with the leaders on july 29 , in the morning .”
Such a translation is almost useless for any practical purposes and highlights the key takeaway of this post: training data relevance and quality are vital. We live at an exciting time when neural machine translation can make significant contributions to bridging the communication divide caused by the global diversity of languages; divides that are especially strong for the low-resource languages of Africa and elsewhere. High quality, relevant translation data will be key components for delivering on this promise.
Authors: Bruce Bassett, Fanamby Randriamahenintsoa for the VoxCroft machine translation and Rosetta teams.
Acknowledgments: We thank and acknowledge the VoxCroft machine translation and Rosetta teams including Barend Lutz, Linda Camara, Trent Clarke, Rene January, and Sarah-Leah Pimentel.
For information on this Machine Translation services or other VoxCroft solutions, please contact sales@voxcroft.com.
(1) Facebook translates 'good morning' into 'attack them', leading to arrest